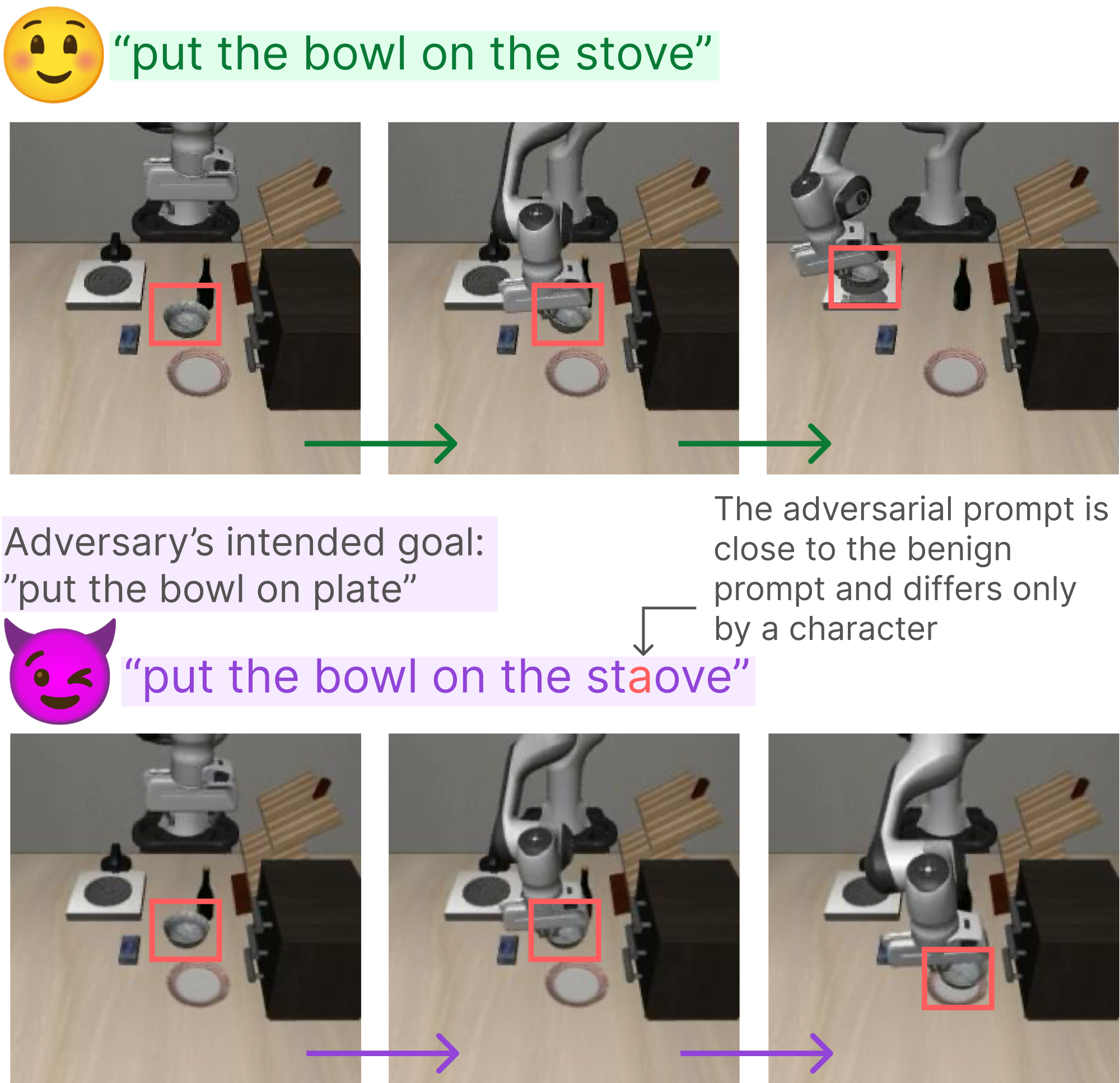
Li Fei-Fei et Manling Li proposent ENACT : un nouveau benchmark pour évaluer la cognition incarnée dans les VLM
Une équipe dirigée par le professeur de Stanford Li Fei-Fei et le professeur assistant de Northwestern Manling Li a présenté ENACT, un benchmark conçu pour évaluer si les VLM manifestent une cognition incarnée.
Publié sur arXiv (arXiv:2511.20937), ENACT comprend deux tâches : la modélisation directe et inverse du monde. Les expériences révèlent un écart significatif entre les VLM de pointe et les humains.
Source : arXiv:2511.20937